8个用于数据挖掘与分析的最佳开源工具
在当今数据驱动的时代,数据挖掘与分析已成为企业决策、科学研究以及技术创新的核心环节。开源工具因其灵活性、成本效益和活跃的社区支持,成为了众多数据分析师、工程师和研究人员的重要选择。以下是8个在数据挖掘与分析领域表现卓越、备受推崇的开源工具,它们各有侧重,共同构成了强大的数据处理生态。
1. Python(搭配Pandas、Scikit-learn等库)
Python无疑是当前数据科学领域的首选语言。其简洁的语法和庞大的生态系统,特别是如Pandas(数据操作与分析)、NumPy(数值计算)、Scikit-learn(机器学习)、Matplotlib/Seaborn(数据可视化)等库,为数据挖掘的各个环节提供了全面支持。从数据清洗、探索性分析到构建复杂的预测模型,Python几乎无所不能。
2. R
R是专为统计计算和图形而设计的语言和环境。它拥有极其丰富的统计软件包(如dplyr、ggplot2、caret),在统计分析、可视化以及学术研究领域有着深厚的基础。对于需要深入统计建模和制作高质量出版级图表的任务,R是极佳的选择。
3. Apache Spark
当处理大规模数据集(大数据)时,Apache Spark脱颖而出。它是一个快速、通用的集群计算系统,提供了高级API(如Spark SQL用于结构化数据处理,MLlib用于机器学习),支持批处理、流处理、交互式查询等多种计算范式,能显著提升海量数据挖掘的效率。
4. Weka
Weka是一个集成了大量机器学习算法的Java平台,特别适合入门学习和快速原型开发。它提供了一个图形用户界面,用户无需编写代码即可进行数据预处理、分类、回归、聚类、关联规则挖掘和可视化,是教学和小型项目的理想工具。
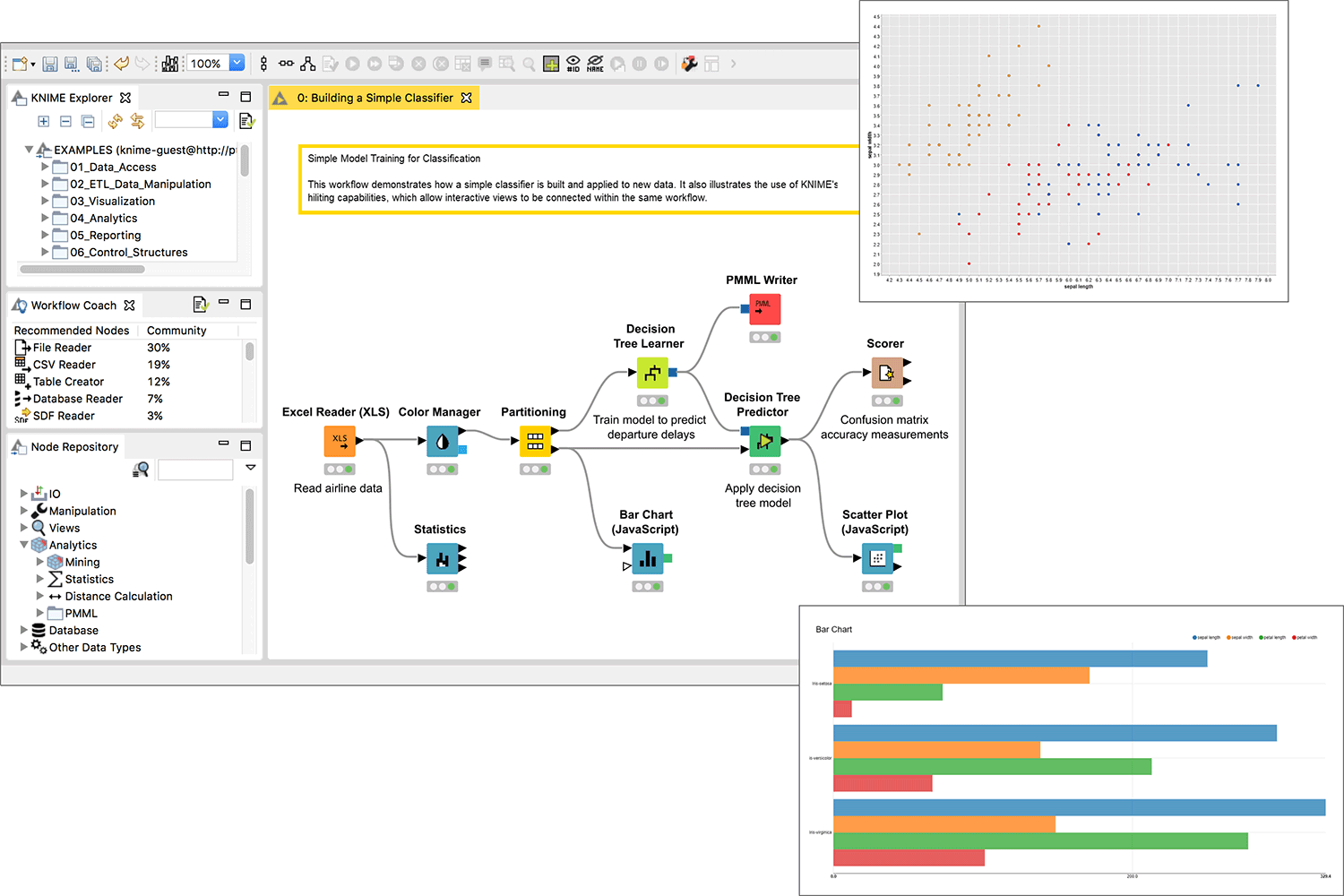
5. KNIME
KNIME(Konstanz Information Miner)是一个基于图形化工作流的数据分析、报告和集成平台。它通过拖放节点(代表数据处理步骤)来构建数据流水线,极大地降低了使用门槛,同时支持集成R、Python、Java等代码,兼具易用性与强大功能。
6. RapidMiner(开源版)
与KNIME类似,RapidMiner也采用可视化工作流设计,提供了从数据加载、转换、建模到验证部署的完整环境。其开源版本功能全面,内置了大量算子和模板,使复杂的数据挖掘过程变得直观和高效。
7. Orange
Orange是一个基于组件的数据挖掘和机器学习软件套件,同样拥有友好的可视化编程界面。其组件称为“小部件”,用户通过连接小部件来构建数据分析流程。Orange在数据可视化方面尤其出色,支持丰富的交互式图表。
8. Elastic Stack(ELK:Elasticsearch, Logstash, Kibana)
对于实时搜索、日志和事件数据分析,Elastic Stack是一个强大的解决方案。Elasticsearch负责搜索和分析,Logstash负责数据采集和处理,Kibana则提供可视化仪表板。它虽然不是传统意义上的“数据挖掘”工具,但在从海量非结构化或半结构化数据(如日志、文本)中提取洞察方面能力非凡。
****
选择合适的工具取决于具体的任务需求、数据规模、团队技能和个人偏好。对于初学者或需要灵活编程的场景,Python和R是基石;面对大数据挑战,Spark不可或缺;若追求快速、可视化的流程构建,Weka、KNIME、RapidMiner和Orange则是得力助手;而ELK栈则在实时日志和文本分析领域独树一帜。熟练掌握其中几种工具的组合,将能有效应对各种数据挖掘与分析挑战,从数据中挖掘出真正的价值。
如若转载,请注明出处:http://www.appzhiku.com/product/30.html
更新时间:2026-06-19 08:47:21